Hacking Academia: Data Science and the University
A reflection on our SciFoo breakout session, where we discussed issues of data science within academia.
Almost a year ago, I wrote a post I called the Big Data Brain Drain, lamenting the ways that academia is neglecting the skills of modern data-intensive research, and in doing so is driving away many of the men and women who are perhaps best equipped to enable progress in these fields. This seemed to strike a chord with a wide range of people, and has led me to some incredible opportunities for conversation and collaboration on the subject. One of those conversations took place at the recent SciFoo conference, and this article is my way of recording some reflections on that conversation.
SciFoo is an annual gathering of several hundred scientists, writers, and thinkers sponsored by Digital Science, Nature, O'Reilly Media & Google. SciFoo brings together an incredibly eclectic group of people: I met philosophers, futurists, alien hunters, quantum physicists, mammoth cloners, magazine editors, science funders, astrophysicists, musicians, mycologists, mesmerists, and many many more: the list could go on and on. The conference is about as unstructured as it can be: the organizers simply provide food, drink, and a venue for conversation, and attendees put together breakout discussions on nearly any imaginable topic. If you ever get the chance to go, my advice is to drop everything else and attend. It was one of the most quirky and intellectually stimulating weekends I've ever spent.
The SciFoo meeting is by invitation only, and given the incredible work of other attendees, I'm still not quite sure how I ended up on the invite list (it was perhaps the worst flare-up of impostor syndrome I've ever had!) I forced myself to get over it, though, and teamed-up with Chris Mentzel, a program director in the Moore Foundation, and led a session: we called it Hacking Academia from Inside and Out. The session was in many ways a conversation around the general topic of my Brain Drain post, though it was clear that many of the folks in attendance had been thinking in these terms long before I penned that particular essay.
The Problem
The problem we discussed is laid out in some detail in my Brain Drain post, but a quick summary is this: scientific research in many disciplines is becoming more and more dependent on the careful analysis of large datasets. This analysis requires a skill-set as broad as it is deep: scientists must be experts not only in their own domain, but in statistics, computing, algorithm building, and software design as well. Many researchers are working hard to attain these skills; the problem is that academia's reward structure is not well-poised to reward the value of this type of work. In short, time spent developing high-quality reusable software tools translates to less time writing and publishing, which under the current system translates to little hope for academic career advancement.
In my Brain Drain post, I observed the rise of data-intensive research and lamented that researchers with the requisite interdisciplinary knowledge are largely unrecognized and unrewarded in academia, even as they are highly-sought-after in the tech industry. I previously labeled this type of person a "new breed of scientist", but since then it's become clear that the working label for this type of person has become (for better or worse) a data scientist.
Defining Data Science
The term "Data Science" generally seems to get a bad rap: it's variously dismissed as misleading, an empty buzzword, or begrudgingly conceded to be flawed, but useful. Perhaps "Data Scientist" can be understood as just a more subdued term for the "sexy statistician" that Hal Varian predicted would become the top career of this decade.
I think the best illustration of data science's definition comes from Drew Conway's Data Science Venn Diagram, which applies the label "Data Science" to the intersection of hacking skills, statistical knowledge, and domain expertise.
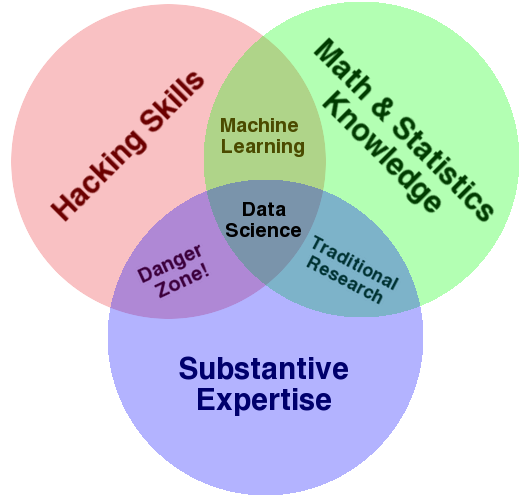
The key is that in addition to the normal depth of knowledge in one's own field, there as a rare breadth to the knowledge and skill-set of a data scientist.
In the words of Alex Szalay, these sorts of researchers must be "Pi-shaped" as opposed to the more traditional "T-shaped" researcher. In Szalay's view, a classic PhD program generates T-shaped researchers: scientists with wide-but-shallow general knowledge, but deep skill and expertise in one particular area. The new breed of scientific researchers, the data scientists, must be Pi-shaped: that is, they maintain the same wide breadth, but push deeper both in their own subject area and in the statistical or computational methods that help drive modern research:
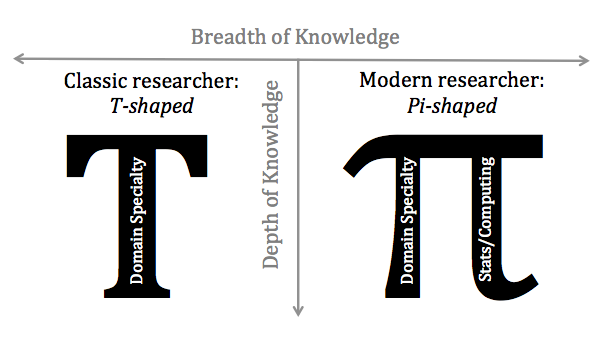
Perhaps neither of these labels or descriptions is quite right. Another school of thought on data science is Jim Gray's idea of the "Fourth Paradigm" of scientific discovery: First came the observational insights of empirical science; second were the mathematically-driven insights of theoretical science; third were the simulation-driven insights of computational science. The fourth paradigm involves primarily data-driven insights of modern scientific research. Perhaps just as the scientific method morphed and grew through each of the previous paradigmatic transitions, so should the scientific method across all disciplines be modified again for this new data-driven realm of knowledge.
Regardless of what metaphor, definition, or label you apply to this class of researcher, it is clear that their skill set is highly valuable in both academia and industry: the brain drain that many have observed comes from the unfortunate fact that academia fails to properly reward the valuable skill set of the data scientist.
Our Discussion: Academia and Data Science
With this label in mind, our SciFoo discussion focused largely around the following questions:
- Where does Data Science fit within the current structure of the university?
- What is it that academic data scientists want from their career? How can academia offer that?
- What drivers might shift academia toward recognizing & rewarding data scientists in domain fields?
- Recognizing that graduates will go on to work in both academia and industry, how do we best prepare them for success in both worlds?
I'll go through some of the thoughts we discussed below:
1. Where does Data Science fit within the current structure of the university?
The question of data science's place in academia drew a variety of responses and ideas:
The "Fourth Paradigm": data science is simply a label for a new skill-set, and shouldn't be separated from the departments in which it is useful. The thinking here is that data science is simply an umbrella term for an essential skill in modern scientific research. For example, laboratory biologists are dependent on pipetting skills: this doesn't mean that the university should create a new "Department of Applied Pipetting". On the contrary, it simply means that pipetting technique should be part of a laboratory biologist's normal training. Similarly, departments across the university should simply incorporate relevant data science techniques into their normal curriculum.
Data science as a consulting service. Perhaps data science is more like Information Technologies (IT). All modern science labs depend on some sort of computer infrastructure, and most universities long ago realized that it's counter-productive to expect their specialized researchers to effectively manage that infrastructure. Instead, IT organizations were created which provide these services to multiple departments. Data science might be treated the same way: we can't expect every scientist to be fluent in the statistical and computational methods required to work with large datasets, so we might instead out-source these tasks to data science experts.
Data science as an applied computer science department. There has been a trend in the 20th-century of academic subjects splitting into "pure" and "applied" sub-domains. Many Universities have departments of "applied math" and "applied physics", which (loosely speaking) distinguish themselves from the non-applied version by employing the techniques of the field within practical rather than theoretical contexts. Perhaps data science is best viewed as an applied branch of computer science or of statistics which should become its own academic department.
Data science as a new role for libraries. It is no secret that digitization is changing the role of libraries on university campuses. The general public thinks of libraries little more than warehouses for books, but those in the field see printed books as just one particular manifestation of their focus, which has always been data curation. Many library scientists I've talked with recently are excited about the role that new methods and technologies can play in this task of curating and extracting information from their stores of data. From this perspective, Library & Information Science departments may be a natural home for interdisciplinary data science.
Data science as a new interdisciplinary institute. A middle ground to the above approaches may be to organize data science within an interdisciplinary institute; this is a common approach for topics that are inherently multi-disciplinary. Such institutes are already common in academia: for example, the University of Washington is home to the Joint Institute for the Study of Atmosphere and Ocean, which brings together dozens of department, schools, and labs to collaborate on topics related to the climate and the environment. Perhaps such an umbrella institute is the place for data science in the University.
2. What is it that academic data scientists want from their job? How can academia offer that?
Moving from university-level issues to personal-level issues, we brainstormed a list of goals that drive data scientists within academia and industry. While scientists are by no means a homogeneous group, most are driven by some combination of the following concerns:
- Salary & other financial compensation
- Stability: the desire to live in one place rather than move every few years
- Opportunity for Advancement
- Respect of Peers
- Opportunity to work on open source software projects
- Opportunity to travel & attend conferences
- Flexibility to work on interesting projects
- Opportunity to publish / freedom from the burden of publishing
- Opportunity to teach / freedom from the burden of teaching
- Opportunity to mentor students / freedom from the burden of mentoring students
I've tried to generally order these from "perks of industry" to "perks of academia" from the perspective of a recently-minted PhD, but this rough one-dimensional categorization misses the variety of opportunities in both worlds. For example, some academic research scientists do not spend time teaching or mentoring students, and some tech industry jobs contain the type of flexibility usually associated with academic research.
Those younger participants in our conversation who have most recently been "in the game", so to speak, especially noted problems in academia with the first three points. Compared to an industry data scientist position, an academic post-doc has some distinct disadvantages:
- Money: the NIH postdoc salary hovers somewhere around $\$$40,000 - $\$$50,000 per year. Industry often starts recent PhDs at several times that salary.
- Stability: before finding a permanent position, it is common now for young scientists to do several short-term post-doctoral appointments, often in different corners of the country. This means that many academics cannot expect to root themselves in a community until their mid-30s or later. For an industry data scientist, on the other hand, there may be many attractive and permanent job options near home.
- Advancement: those who focus on software and data in academia, rather than a breakneck pace of publication, have little hope for a tenure-track position under the current system. A researcher who spends significant time building software tools can expect little reward within academia, no matter how influential those tools might be.
Anecdotally, these seem to be the top three issues for talented data scientists in academia. With the tech-industry market for data scientists as hot as it is, skilled PhD candidates have many compelling incentives to leave their field of research.
3. What drivers might shift academia toward recognizing & rewarding data scientists in domain fields?
We discussed several drivers that might make academia a more friendly place for data scientists. Generally, these centered around notions of changing the current broken reward structure to recognize success metrics other than classic publication or citation counts. These drivers may be divided into two different categories: those outside academia who might push for change (e.g. funding agencies, publishers, etc.) and those inside academia who might implement the change themselves (e.g. university leadership and department leadership). We discussed the following ideas:
From the outside:
- Publishers might provide a means of publishing code as a primary research project. Introducing a DOI for software with easy means of updating contributor lists over time, for example, might lead to increased citation and recognition of alternative research activities.
- Publishers might push for reproducibility as a requirement for publication. Reproducibility of data-intensive research requires the well-engineered code that data scientists can produce, and would increase the value placed on these skills.
- Funding agencies might provide funding specifically for interdisciplinary data scientists within specific domain fields.
- Funding agencies might encourage interdisciplinary collaboration through specific grant requirements.
From the inside:
- University leadership might set aside funding for new data science departments or for interdisciplinary institutes focused on data science.
- University leadership might create joint positions: e.g. paying half of a professor or researcher's salary so that he or she can focus that time on tasks such as creating, maintaining, or teaching about important software tools.
- Department leadership might take the lead to adapt their curriculum to include data science topics, and specifically hire faculty who emphasize these areas in their work.
- Department leadership might adjust their hiring practice to recognize alternative metrics that go beyond the H-index: for example, recognizing the importance of an open source software tool that is well-used, but may not generate a classic citation record.
4. Recognizing that graduates will go on to work in both academia and industry, how do we best prepare them for success in both worlds?
This question is the flip-side of the Brain Drain theme: the number of PhDs granted each year far exceeds the number of academic positions available, so it is simply impossible for every graduate to remain in academia.
This is, for some reason, a somewhat taboo subject in academia: I've talked to many who at the end of their PhD program were leaning toward leaving academia, and dreaded having "the talk" with their thesis advisor. But academic departments should take seriously the job prospects for their graduates, and that involves making sure they have marketable skills upon graduation.
Fortunately, these marketable skills overlap highly with the skills that can lead to success in modern data-intensive scientific research: the ability to design and write good software, to create tools that others can reuse, to collaboratively work on large software projects, to effectively extract insight from large datasets, etc. Unfortunately, development of this skill set takes time and energy at the level of both graduate coursework and research mentorship. Departments should push to make sure that their students are learning these skills, and are rewarded for exercising them: this will have the happy side-effect of increasing demand within academia for the scientists who nurture these skills.
Hacking Academia: How is this problem being addressed?
At the beginning of the SciFoo conference, each of the ~250 people present were invited to introduce themselves with a one line description of who they are and what they spend their time thinking about. The title of this post, Hacking Academia, is a phrase that I borrowed from Chris Mentzel's one-line description of his own focus.
This is hacking not in the Hollywood sense of using computers for malicious purposes, but hacking in the sense of working within a rigid system to accomplish something it is not necessarily designed to do. This type of "institutional hacking" is the best description of what we're after: finding shortcuts that will mold the world of academic scientific research into a more effective version of itself.
Complaining about the state of academia is a favorite past-time of academics, but it is far rarer to see actual solutions to these problems. One of the best pieces of the SciFoo discussion was just this: hearing about the steps that various individuals, foundations, and institutions are taking to address the concerns outlined above. I'll mention a few examples here:
UW, Berkeley, NYU: The Moore-Sloan Initiative
As I mentioned, my co-conspirator in leading this session was Chris, whom I know through his involvement with the recent Moore-Sloan Data Science Initiative. For years within his role in the Moore Foundation, Chris has been thinking about these issues from the perspective of a funder of scientific research. His efforts in this area have recently led to this $\$$38 million initiative, which is built around a five-year grant to three institutions: University of Washington, University of California Berkeley, and New York University. One of the primary and explicit goals of the grant is to jump-start new career paths for data scientists in scientific domain fields, and each of the three universities has a team who is approaching the work in their own way.
In January, I was hired by UW's eScience Institute to help lead the UW portion of this effort. We are in the middle of building a data science studio space that will be a central hub for multi-disciplinary data-intensive research on campus, and are currently in the process of hiring our first round of interdisciplinary postdocs, data scientists, and research scientists. These positions are designed especially to attract those skilled "Pi-shaped" researchers who may fall through the cracks in classic academic tracks, and we place particular value on alternative metrics such as open source contributions and efforts toward reproducibility. Berkeley and NYU are undertaking similar efforts on their own campuses with the Berkeley Institute for Data Science and NYU's Center for Data Science.
The Moore Foundation: Data Driven Discovery
The Moore Foundation is not stopping with this Data Science Initiative. They will soon be announcing their Data Driven Discovery grant winners: 14 individuals who will split a total of $\$$21 million over five years, along with up to $\$$9 million in additional grants to scale-up specific data-driven software and methods. The Moore foundation seems intent on using their endowment to effect real change in this area, and I am excited to see the results (I can assure you that I'm not just saying this because they currently pay my salary!)
NSF: the IGERT program
The NSF's long-standing Interactive Graduate Education and Research Traineeship (IGERT) program provides funding for interdisciplinary training for PhDs and postdocs, and recent grants in particular have had a data science focus. UW was recently awarded an IGERT grant for an interdisciplinary data-focused PhD program, and the first group of these students will be starting this fall. An important piece of this was that home departments agreed to allow these students to forego some of their normal degree requirements to make room for joint courses on data science skills and techniques. IGERT remains an active NSF program, and has similar interdisciplinary grants to schools and departments around the United States.
UW: Provost's Data Science Initiative
At UW, the university-wide leadership is also thinking along these lines with some concrete actions of their own: the provost has set aside funding for half-positions to encourage hiring of interdisciplinary faculty. The next Astronomy professor hired by UW, for example, might spend half of his or her time working and teaching through the eScience institute on general computational and data science methods.
Publishing Code: the Journal of Statistical Software
Though this isn't a recent initiative, the Journal of Statistical Software (JSS) is an example of a non-profit publisher which is having a positive impact in the area of statistical software, by giving scientists a forum to publish the software they write and cite the software they use. Perhaps in part because of the extreme usefulness of well-written, reusable software, JSS is very highly-ranked (see, for example, the SCImago rankings). More journals like this, which place explicit value on reproducible computation and well-written software tools, could be a huge benefit to the academic data scientist. (full disclosure: I'm on the editorial board of JSS).
Harvard University: Initiative in Innovative Computing & Institute for Advanced Computational Science
Alyssa Goodman of Harvard was part of our discussion, and mentioned that nearly a decade ago Harvard foresaw and began addressing the value of interdisciplinary data-intensive science and research. They created a short-lived Initiative in Innovative Computing (IIC), which existed from 2005-2009, until the global financial crisis led its funding to be cut. At its peak, the IIC was supported to the tune of around $4 million per year and was home to roughly 40 staff, most working jointly between the IIC and other departments. After the IIC funding dissipated, it seems that most of this momentum (and many of the IIC staff) moved to the Harvard's Institute for Advanced Computational Science (IACS), started by Tim Kaxiras and the Harvard School of Engineering in 2010. Though IACS has traditionally focused more on simulation and computation, it has recently begun to branch out to visualization and data science as well. Alyssa seems optimistic that momentum in this area is again building, and mentioned also Harvard's Institute for Quantitative Social Science, the Seamless Astronomy Program, and the Library as key players.
Michigan State: new Applied Computation Department
Another active participant in the discussion was Steve Hsu, Vice President for Research at Michigan State University. He shared some exciting news about a new development at Michigan State: the creation of a new department, tentatively called Applied Computation and Mathematics. According to Steve, MSU will soon be hiring around twenty interdisciplinary tenure-track faculty, who will have one foot in their home department and one foot in this new department. MSU already has many impressive researchers working in data-intensive areas across the university: with this effort I'm excited to see the dynamic interdisciplinary community they will build.
Conclusion
The SciFoo discussion was excellent, as was the weekend as a whole: I would like to take this chance to thank O'Reilly Media, Digital Science, Nature Publishing Group, and Google for making it all possible.
Nearly a year after my Brain Drain brain dump, I am thrilled to see that there are so many good people thinking about and working on these problems, and so many real solutions both in process and on the horizon. While the lure of a well-funded tech industry will doubtless still attract a steady stream of scientists away from their academic research, I'm heartened to see such focused effort toward carving-out niches within academia for those who have so much to contribute.